Was ist ein Crawler?
Ein Crawler, auch Robot, Bot, Spider, Searchbot oder Webcrawler genannt, ist ein Programm was selbständig das World Wide Web durchsucht und Inhalte, Informationen ausliest und indexiert. Abgeleitet von der Suchmaschine „WebCrawler“ welche 1994 als erste öffentlichte Suchmaschine mit Volltextindex-Suche arbeitete.
Crawler in einem Video erklärt

In diesem Video erklären wir den Begriff „Crawler“
Infografik zum Begriff Crawler
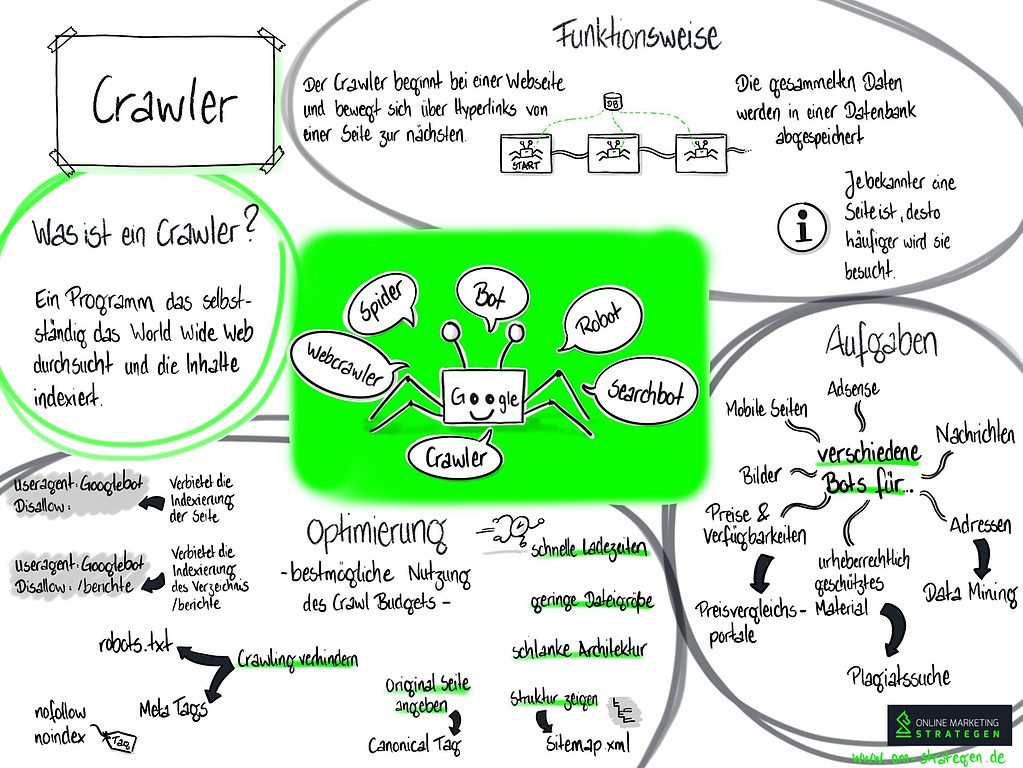
Infografik zum Begriff Crawler
Wie funktioniert ein Crawler?
Angestoßen durch einen Hyperlink einer Website, durchforstet der Crawler das Internet und gelangt so von Website zu Website, die daraus gesammelten Daten werden wiederum in einer Datenbank abgelegt. Die Algorithmen bestimmen hierzu wie oft eine Website gecrawlt wird, je bekannter die Seite desto häufiger wird diese besucht.
Welche Informationen ein Crawler aufnimmt, hängt von dessen Aufgabenstellung ab:
- Preisvergleichsportale suchen nach Produkten, deren Verfügbarkeit und Preise ab
- Im Data Mining werden Crawler zur Generierung von Adressen eingesetzt
- News der Nachrichtenportale werden gecrawlt
- Plagiatssuche nach urheberrechtlich geschützten Material im Netz
Google nutzt hierzu verschiedene Bots sei es für Adsense, Mobile Seiten, Bildersuche, News.
Wie lassen sich Crawler aussperren oder steuern?
Mittels der robots.txt können Sie das Crawling verhindern. Beispiel:
- User-agent: Googlebot
Disallow:
In diesem Beispiel darf der Googlebot die Seite nicht besuchen - User-agent: Googlebot
Disallow: /berichte
In diesem Beispiel wird dem Googlebot die Indexierung des Verzeichnis /berichte untersagt
Mit Hilfe der Meta-Tags „nofollow“ oder „noindex“ ist es ebenfalls möglich dem Crawler mitzuteilen welcher Seite er nicht folgen oder indexieren soll. Durch das Canonical Tag können Sie dem Crawler die Original-Seite mitteilen bzw. durch eine Sitemap.xml die Struktur aufzeigen.
Crawler und die Suchmaschinenoptimierung
In der SEO sollte es von Interesse sein, Crawler gezielt auf der eigenen Website zu steuern. Jede Website besitzt ein Crawl Budget, so dass dieses bestmöglich für diese eingesetzt werden sollte. Durch gezielte Steuerung oder dem Aussperren, lässt sich dieses so effektiv wie möglich einsetzen. Achten Sie hierzu auf schnelle Ladezeiten, geringe Dateigrößen und schlanke Websiten-Architektur.
Weiterführende Links
Die Google Crawler: https://support.google.com/webmasters/answer/1061943?hl=de&ref_topic=9426101
Der Crawling Prozess: https://www.google.com/intl/de/search/howsearchworks/crawling-indexing/