Was ist die Robots.txt?
Die robots.txt (Robots Exclusion Standard Protokoll – REP) ist eine reine Textdatei (kein HTML) in UTF-8 Kodierung, die seitens des Webmasters erstellt wird um den Suchmaschinen-Bots klare Anweisungen zu erteilen, welche Inhalte gecrawlt werden dürfen und welche nicht. Suchmaschinen wie Google, Yahoo oder Bing halten sich an die Anweisungen in der robots.txt.
Robots.txt in einem Video erklärt

In diesem Video erklären wir dir die „Robots.txt“
Infografik zum Einsatz der Robots.txt
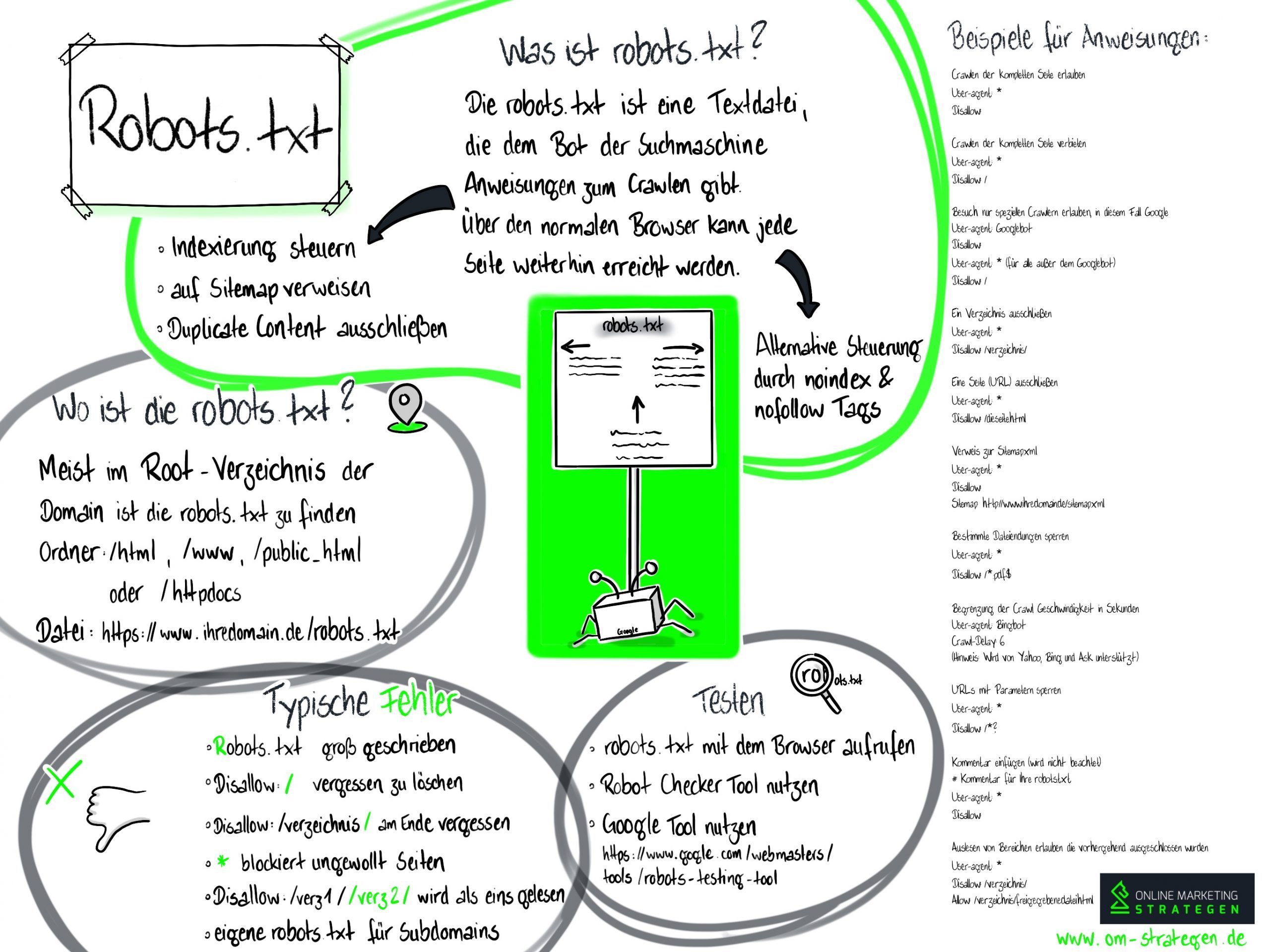
Infografik zu Robots.txt
Wo finden Sie die robots.txt?
Die Robots.txt, die maximal 500kb groß sein darf, wird meist im sogenannten Root-Verzeichnis einer Domain abgelegt. Dies kann je nach Webhoster der Ordner /html, /www, /public_html oder /httpdocs sein. Die Datei selbst nennt sich wiederum robots.txt: https://www.ihredomain.de/robots.txt
Warum ist eine robots.txt notwendig?
- Steuerung Indexierung: Haben Sie Inhalte auf Ihrer Domain, die nicht gecrawlt werden sollen, z.B. eine Testumgebung einer neuen Homepage, so empfiehlt sich der Einsatz einer robots.txt. Es kann verboten werden alles zu indexieren, sei es auf der Domain oder Subdomain, Verzeichnisse zu spidern, Dateien oder einzelne URLs zu crawlen.
- Sitemap: Innerhalb der robots.txt verweisen Sie auf die sitemap.xml, die eine Übersicht Ihrer Domain darstellt.
- Duplicate Content: Bieten Sie Inhalte zugleich als Druckversion an, so schließen Sie diese mittels der robots.txt aus, um Duplicate Content zu vermeiden.
Beispiele von Anweisungen in der Robots.txt
- Crawlen der kompletten Seite erlauben
User-agent: *
Disallow: - Crawlen der kompletten Seite verbieten
User-agent: *
Disallow: / - Besuch nur speziellen Crawlern erlauben, in diesem Fall Google
User-agent: Googlebot
Disallow:
User-agent: * (für alle außer dem Googlebot)
Disallow: / - Ein Verzeichnis ausschließen
User-agent: *
Disallow: /verzeichnis/ - Eine Seite (URL) ausschließen
User-agent: *
Disallow: /dieseite.html - Verweis zur Sitemap.xml
User-agent: *
Disallow:
Sitemap: http://www.ihredomain.de/sitemap.xml - Bestimmte Dateiendungen sperren
User-agent: *
Disallow: /*.pdf$ - Begrenzung der Crawl Geschwindigkeit in Sekunden
User-agent: Bingbot
Crawl-Delay: 6
(Hinweis: Wird von Yahoo, Bing und Ask unterstützt) - URLs mit Parametern sperren
User-agent: *
Disallow: /*? - Kommentar einfügen (wird nicht beachtet)
# Kommentar für Ihre robots.txt
User-agent: *
Disallow: - Auslesen von Bereichen erlauben die vorhergehend ausgeschlossen wurden
User-agent: *
Disallow: /verzeichnis/
Allow: /verzeichnis/freigegebenedatei.html
Welche Google Crawler gibt es?
| Crawler | User-Agent |
| Googlebot (Google Websuche) |
Googlebot |
| Googlebot Nachrichten | Googlebot-News |
| Googlebot Bilder | Googlebot-Image |
| Googlebot Videos | Googlebot-Video |
| Google Mobile Adsence | Mediapartners-Google oder Mediapartners |
| Google AdSense | Mediapartners-Google oder Mediapartners |
| Google AdsBot | AdsBot-Google |
Weitere Bots sind:
| Slurp | Yahoo |
| Msnbot / bingbot | MSN oder Bing |
| Teoma | ASK |
Tool zum testen der Robots.txt
- Eine Möglichkeit Ihre Robots.txt zu testen, ist der Aufruf dieser mittels Ihrem Browser:
https://www.ihredomain.de/robots.txt , werden Ihnen Inhalte angezeigt, so existiert diese. - Eine weitere Möglichkeit ist z.B. der Einsatz eines Robots Checker Tools: http://tools.seobook.com/robots-txt/analyzer/
- Auch Google stellt ein Tool zum testen der Robots.txt zur Verfügung, hierzu ist jedoch ein Google Account notwendig: https://www.google.com/webmasters/tools/robots-testing-tool
Was mit der robots.txt nicht geht
Möchten Sie eine Seite vor einem Aufruf schützen, so ist dies mittels der Robots.txt nicht möglich! Die ausgeschlossenen Seiten, Dateien oder Verzeichnisse sind weiterhin normal mittels einem Webbrowser aufrufbar.
Alternative zur Robots.txt
Das Crawling von HTML Seiten lässt sich auch durch Kennzeichnung im HEAD der Website steuern:
- Indexierung und folgen der Links freigegeben
<meta name=“robots“ content=“index,follow“ /> - Indexierung und folgen der Links nicht freigegeben
<meta name=“robots“ content=“noindex,nofollow“ /> - Indexierungsverbot, Links weiter verfolgen
<meta name=“robots“ content=“noindex,follow“ />
Häufige Fehler beim Einsatz der robots.txt
- Robots.txt statt robots.txt
robots.txt eine andere Datei als die Robots.txt. - Disallow: /
Häufig nach einem Relaunch vergessen zu entfernen. Die Indexierung wird verhindert - Slash vergessen
Möchten Sie ein Verzeichnis sperren, so beenden Sie diese mit dem „/“ Slash, z.B.
Disallow: /verzeichnis/ - Wildcard verhindert Indexierung
Schließen Sie beispielsweise mit einer Wildcard „Disallow: /*temp“ Dateien aus, so können auch gleichlautende URLs davon betroffen sein /temperaturen-europa.html - Disallow: /log/ /bilder/
Der Crawler unterscheidet nicht zwischen den Verzeichnissen, d.h. er liest diesen Befehl als einen Pfad - Subdomain aussperren
Eine Subdomain benötigt in Ihrem Root-Verzeichnis eine eigene robots.txt, übergreifend ist dies nicht möglich
Robots.txt und die Suchmaschinenoptimierung
Ausgehend der Suchmaschinenoptimierung (SEO) ist die robots.txt einer der ersten Punkte die in der Prüfung vollzogen werden sollten, da eine optimierte Seite nicht in den Index findet, sofern man Ihr das Crawling untersagt. Gerade im Hinblick auf das Crawl-Budget als auch zur Steuerung der Crawler ist die Robots.txt ein wichtiges Hilfsmittel. Sollte eine Seite dennoch im Index aufgenommen werden, so kann dies anhand der eingehenden Backlinks entstehen, Google hält diese Seite dennoch für relevant, zeigt jedoch kein Snippet an. Achten Sie auch in Sachen Bilder SEO, dass Ihr Bilder-Verzeichnis nicht unbedingt gesperrt wird, denn so verhindern Sie auch hier gute Rankings für Ihre Website.
Weiterführende Links
Robots.txt Spezifikationen: https://developers.google.com/search/reference/robots_txt?hl=de
Robots.txt Generator: https://de.ryte.com/free-tools/robots-txt-generator/