Was ist der Google Index?
Stell Dir den Google Index wie eine Datenbank vor, mit Webseiten und Dateien, die von Google gefunden wurden, und deren Beziehung zueinander. Dieser Index ist keinesfalls statisch. Durch das Crawlen durch die sogenannten GoogleBots, wird dieser stetig erweitert bzw. aktualisiert. Der Index spielt eine wichtige Rolle bei der Suche, da er es den Nutzern ermöglicht, Informationen aus dem Internet zu finden. Wenn du „googelst“, sucht Google nach den Wörtern in deiner Anfrage, ordnet dieser deiner Suchintention zu und gibt dir Ergebnisse aus dem eigenen Index zurück. Du siehst dann die sogenannte SERP (Search Engine Result Page), bestehend aus Bildern, Anzeigen, organischen Treffern u.v.m.
Was bedeutet Indexierung?
Durch den Googlebot werden Inhalte auf Websites (Bilder, Texte, Videos u.sw.) mittels interner als auch externer Verlinkungen gefunden und fortan regelmäßig durch die Crawler überprüft. Diese Informationen werden dann in den Google-Index ,nach bestimmten Kriterien, aufgenommen und weiterverarbeitet. Google nutzt hier verschiedene Arten von Crawler mit unterschiedlichen Zielen.
Wie kommt meine Website in den Google Index?
Es gibt verschiedene Möglichkeiten seine Website oder dazugehörige Unterseiten in den Google Index zu bekommen:
- Verlinkungen: Wenn eine andere Website einen Link zu einer deiner Unterseiten enthält und Google in der Lage ist, diesen Link zu finden, werden diese entsprechende Unterseite gecrawlt und in den Index aufgenommen. Gleichermaßen verhält es sich bei internen Links auf deiner Website.
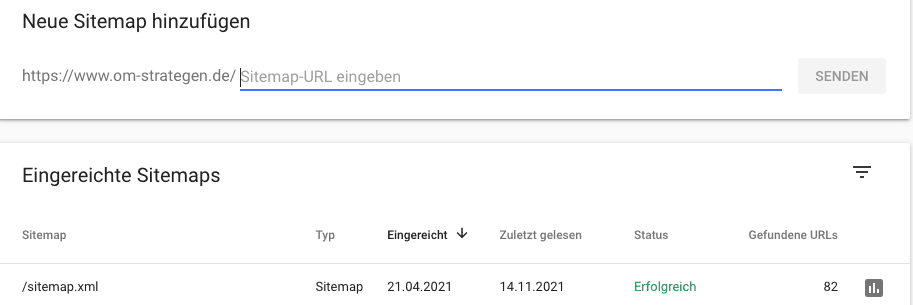
- Sitemap: Wenn du ein Inhaltsverzeichnis, deiner Website, mit dem Namen „Sitemap.xml“ besitzt, hast du die Möglichkeit diese wiederum mittels der Google Search Console einzureichen. Google spidert dann die entsprechenden Dokumente.

- Google Search Console: Innerhalb der Google Search Console hast du die Möglichkeit eine URL zu prüfen und hier eine „Indexierung beantragen“So sendest du gezielt den Crawler auf eine bestimmte URL.

Wie verhindere ich die Indexierung von Inhalten?
Aus unterschiedlichen Gründen kann es notwendig sein, dass man bestimmte URLs oder Dokumente nicht im Google Index auffindbar haben möchte. Möglichkeiten um die Indexierung zu steuern und somit die Aufnahme von Inhalten zu verhindern sind:
- Robots.txt: Mit der robots.txt-Datei im Stammverzeichnis einer Website kannst du Suchmaschinen-Crawler anweisen, bestimmte Teile deiner Website nicht zu crawlen oder zu indizieren. Sei es Verzeichnisse oder Parameter in URLs
- Meta Tag „noindex“: Mit dem Meta-Tag „noindex“ kannst du Crawler anweisen, eine einzelne Seite nicht zu indexieren
- Canonical Tag: Mit dem kanonischen Tag kannst du angeben, dass mehrere URLs auf einen anderen Inhalt verweisen, z.B. Session IDs, Parameter u.v.m. Siehe auch: Duplicate Content
- Nofollow Tag: Mit dem Meta-Tag „nofollow“ kannst du angeben, dass bestimmte Links von den Crawlern der Suchmaschinen nicht verfolgt werden sollen
Wie bekomme ich URLs aus dem Index?
Um eine URL wieder aus dem Google Index zu entfernen gibt es obengenannte Möglichkeiten, diese zu sperren, so dass bei einem erneuten Crawling diese entfernt werden. Andererseits kann es sich auch um kritische Themen handeln, so gibt es hierzu zwei Möglichkeiten:
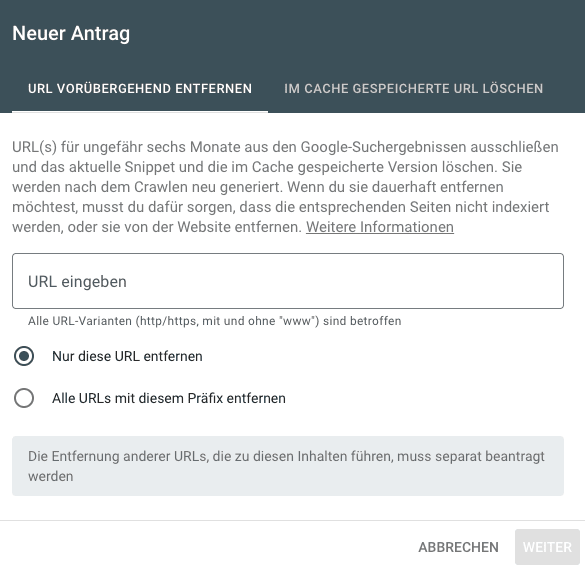
- Search Console: Innerhalb der Search Console besteht die Möglichkeit des „Entfernen“, man kann hier einen Antrag zur Entfernung von Inhalten stellen


- Eine weitere Möglichkeit ist einen Statuscode 410 für eine URL auszugeben oder die URL per 301 auf eine andere URL umzuleiten.
Wie sehe ich ob eine Seite indexiert ist?
Nutze hierzu entweder in der Google Search Console den Punkt „URL-Prüfung“ oder im Google-Suchschlitz die „site:“-Abfrage . Mittels der Site-Abfrage besteht auch die Möglichkeit Kombinationen zu tätigen, z.B.
site:domain.de/deineurl.html -> zeigt exakt diese URL an
site:domain.de intitle:test -> zeigt alle URLs deiner Website an die im Meta-Title den Begriff „Test“ beinhalten
site:domain.de intext:abc -> zeigt alle URLs der Website die im Text „abc“ besitzen
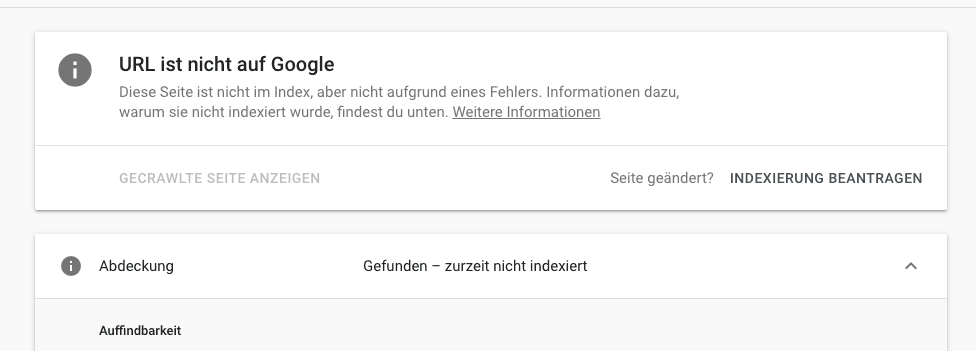
Was bedeutet gecrawlt zurzeit nicht indexiert?
Sofern in der Google Search Console der Hinweis „gecrawlt, zurzeit nicht indexiert“ ausgewiesen wird, so kann es mit Qualitätsproblemen der Seite zusammenhängen. Diese stellt wohlmöglich keinen Mehrwert für die Nutzer dar bzw. es kann sich auch um Duplicate Content handeln.
Weitere Informationen zum Suchmaschinenindex in Verbindung mit dem Crawl-Budget und häufigen Problemen findest du im Artikel „Suchmaschinenindex“
Nicht im Index, kein Traffic
Unsaubere Methoden in der Suchmaschinenoptimierung, sorgen für die deindexierung einer URL, über Verzeichnisse bis hin zur gesamten Domain. Diese können sein:
- Hacking: Die Website wird gehackt, indem Schadcode eingefügt wird
- SPAM Links: zahlreiche eingehende bzw. ausgehende SPAM Links, bzw. durch Linknetzwerke
- Cloaking: Du täuscht dem Crawler andere Inhalte vor
- Dauerhafter 503, 404 oder 410 Fehler von URLs
Es besteht die Möglichkeit über die Google Search Console einen „Antrag auf erneute Prüfung“ zu stellen. Hinweise zu einer Abstrafung finden sich ebenfalls in der Search Console.