Seiten für die Google Indexierung mittels dem Meta-Tag „noindex“ ausschließen.
Was bedeutet noindex?
Der Eintrag „noindex“ in den Meta-Tags der Website, teilt dem Suchmaschinen Crawler mit, besagte Internetseite/URL nicht in den Suchmaschinenindex mit aufzunehmen. Mit den Attributen „follow“ oder „nofollow“ kann dieser ergänzt werden. Das Crawling-Budget wird hierfür verbraucht, da der Google Bot die Seite aufrufen muss, jedoch belastet dies kein Index-Budget der Website.
Noindex in einem Video erklärt

In diesem Video erklären wir den Begriff „Noindex“
Infografik zum Thema Noindex
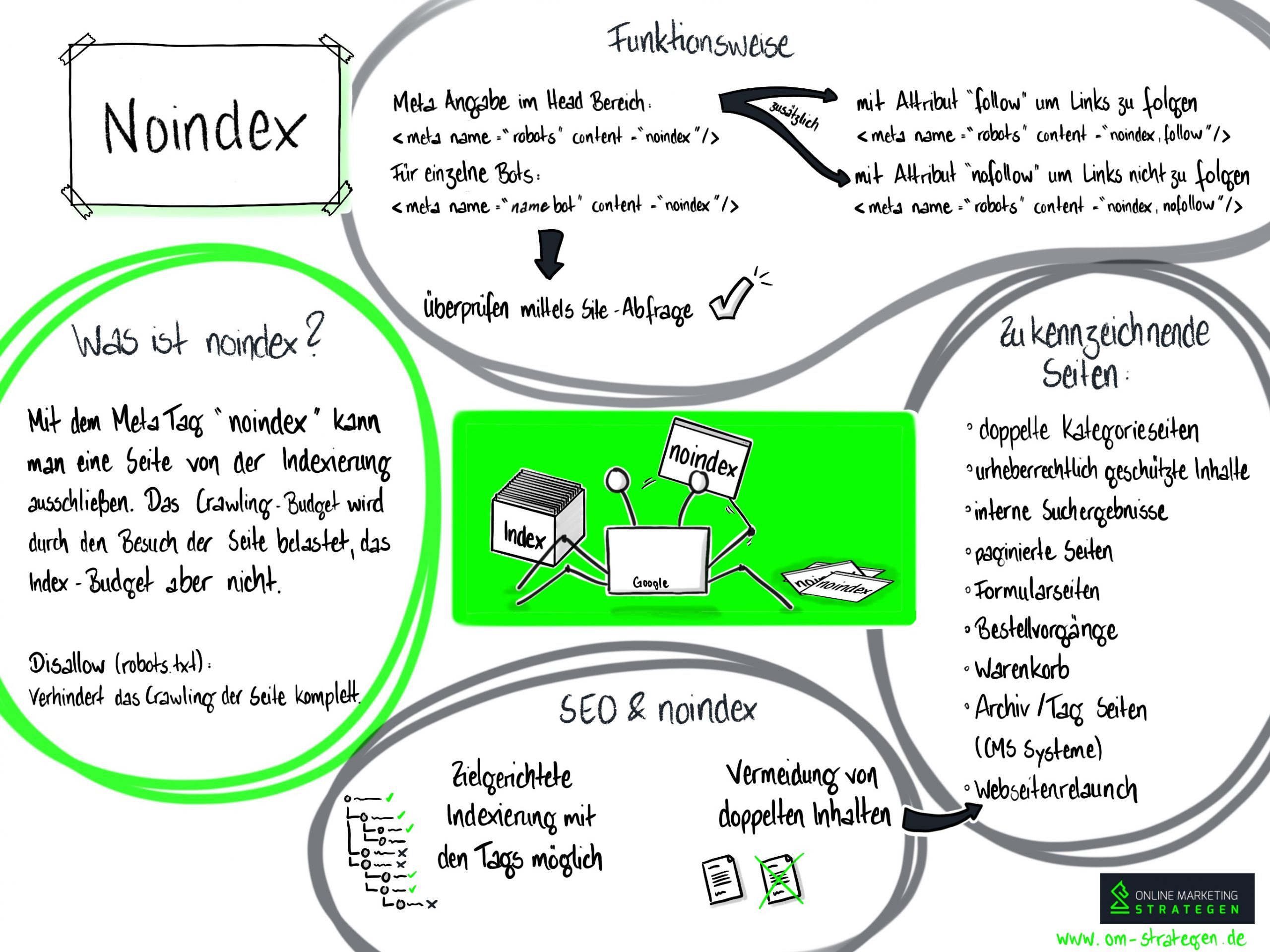
Infografik zu Noindex
Welche Seiten auf noindex setzen?
Das noindex Tag kann nützlich sein um Inhalte, wie folgt, auszuschließen:
- doppelte Kategorieseiten, z.b. in einem Shop
- urheberrechtlich geschützte Inhalte
- interne Suchergebnisseiten (eine interne Suche, z.b. in einem Shop)
- paginierte Seiten
- Formularseiten
- Bestellvorgänge
- Warenkorb
Einbindung des Noindex Tags
Im Quelltext einer Seite (Head Bereich) lässt sich mittels folgender Meta-Angabe die Indexierung der URL verhindern:
<meta name=“robots“ content=“noindex“ />
Somit werden die Inhalte nicht indiziert und sind nicht in Google findbar. Um zu prüfen ob Ihre URL indexiert ist, sollten Sie eine Site-Abfrage durchführen.
Es ist weiterhin möglich, gezielte Suchmaschinen Bots an der Indexierung zu verhindern:
- Bing-Bot: <meta name=“bingbot“ content=“noindex“>
- Google-Bot: <meta name=“googlebot“ content=“noindex“>
Was bewirken die Attribute follow bzw. nofollow?
Das noindex Tag lässt sich um die beiden Attribute „follow“ und „nofollow“ erweitern. Um zu bewirken, dass beispielsweise der Google Bot eine Seite nicht in den Index aufnimmt, den Links auf dieser aber wiederum folgt:
<meta name=“robots“ content=“noindex,follow“ />
Eine Seite nicht in den Index indizieren zu lassen und auch keinen Links zu folgen, wie folgt:
<meta name=“robots“ content=“noindex,nofollow“ />
Das Verwenden eines Canonical Attributs, in Kombination des Noindex-Tags sollte vermieden werden. Zum einen zeigen Sie mittels dem Canonical Tag, dass dies evtl. die originale Seite ist, jedoch schließen Sie wiederum die Indexierung aus.
Noindex und Disallow
Der Befehl „Disallow“ in der robots.txt ist nicht identisch mit dem Noindex Attribut. Durch das Noindex Tag verhindert man eine Indexierung einer Webseite, jedoch nicht das Crawlen dieser. Der Disallow Befehl in der robots.txt verhindert jedoch das Crawling durch die Suchmaschine. Die Kombination in der SEO zwischen Disallow in der robots.txt als auch das Noindex sollte mit Bedacht gesteuert werden.
Nutzen des Noindex Tag für die SEO
Doppelte Inhalte können mittels dem Noindex Tag in der Suchmaschinenoptimierung vermieden werden. Durch die Attribute „follow“ und „nofollow“ ist eine Steuerung des Bots und damit zielgerichtete Indizierung möglich. Gerade CMS Systeme, wie WordPress, legen automatisiert zahlreiche Archive/Tag Seiten an, welche unter Umständen nicht in den Index gelangen sollten und somit unnötig Ihr Index-Budget verbrauchen. Auch bei einem Webseitenrelaunch empfiehlt sich der Einsatz des Noindex Tag um Duplicate Content mit der bestehenden Homepage zu vermeiden.
Weiterführende Links
Eine Liste der Google Crawler: https://support.google.com/webmasters/answer/1061943
Meta Tags die Google versteht: https://support.google.com/webmasters/answer/79812?hl=de